In the new MyJYU AI Transcription service, AI automatically transcribes and if necessary, also translates interview material. The service is aimed for all JYU staff members and students doing research (like a thesis).
Important information
On March 10th 2025, the application has been updated to require device-level biometric recognition (fingerprint or face). Before recording, check that you have the latest version of the MyJYU app installed on your phone and that the biometric recognition is in use. You can enable biometric recognition from your device's settings. Instructions on how to activate biometric recognition on your phone
MyJYU AI Transcription is suitable also for recording of sensitive data if your phone's operating system has been updated to the latest version and supports the latest updates. The app will also give you a notification if a recent enough system version has not been installed on your device.
If you need to record and transcribe sensitive data, but your device does not support the latest system updates or biometric recognition, data can be recorded with Zoom when following JYU's security instructions: link to the Zoom instructions. Students whose device and MyJYU application updates are up-to-date can also use MyJYU AI Transcription for sensitive data.
Data falling under secondary use of health and social data should not be processed in the MyJYU AI Transcription and Researchvideo systems. Please note that most new data produced for research purposes do not involve secondary use of health and social data.
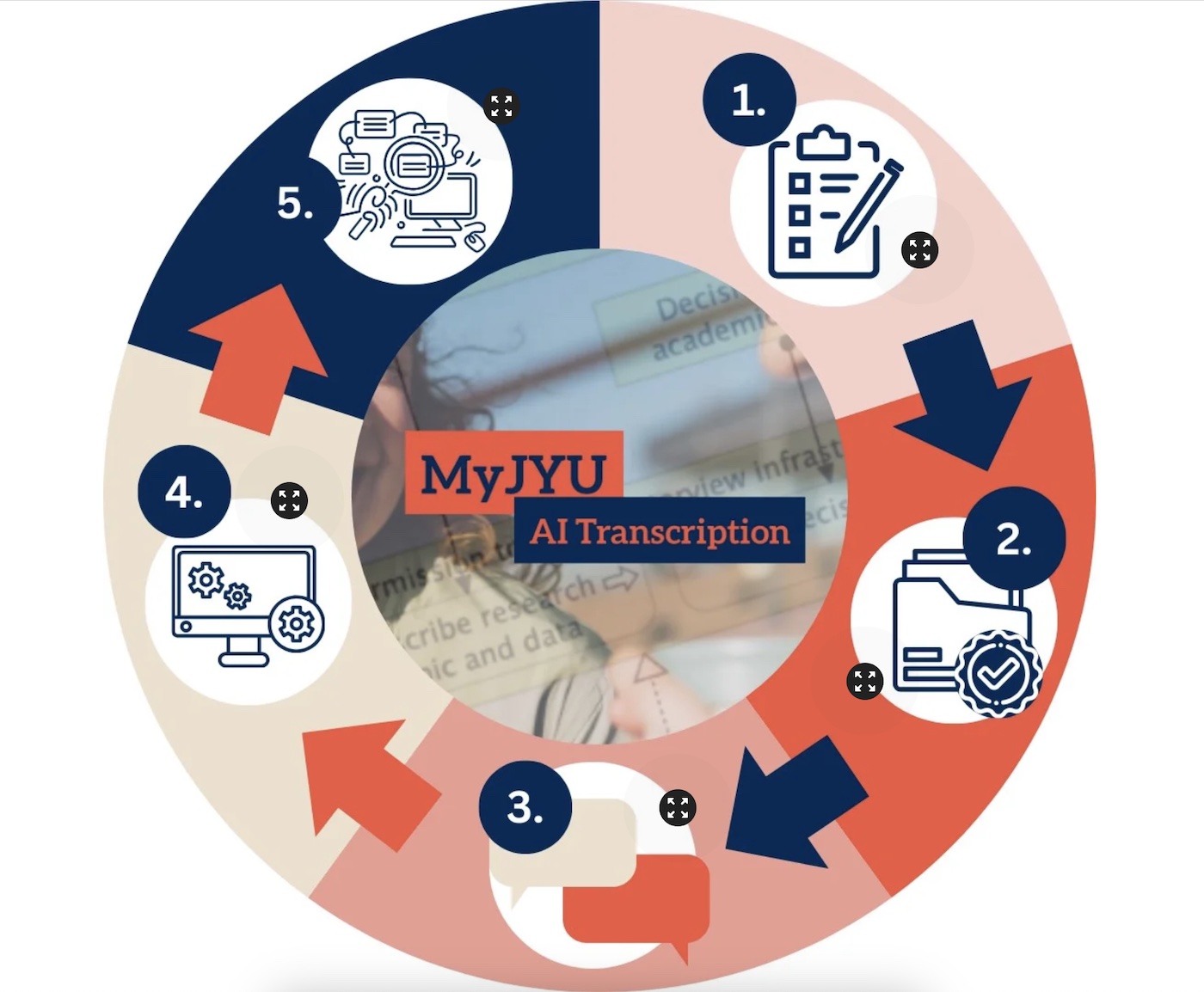
How does it work?
Apply for permissions in Vasara (Processes > MyJYU AI Transcription > Create New)
Record an interview in MyJYU
Upload the audio to Reasearchvideo for transcription
Playback the audio and edit or download the transcriptions in Researchvideo
In case there is something you wish to ask about the service or if you are facing issues when using MyJYU AI Transcription, you may contact the support and maintenance team by filling in the following form: MyJYU AI Transcription HelpJYU form
MyJYU AI Transcription instruction video (in Finnish, English subtitles available)
Ari Lehtiö demonstrates how MyJYU AI Transcription works. 22 mins.
NOTE: Before exporting/downloading files from Researchvideo, make sure that your browser settings direct the download to the intended secure storage location.
Description of the service and model clauses for funding applications
Description and model clause (long)
When conducting research, interview data (audio) is collected using the MyJYU AI Transcription mobile application, developed by the University of Jyväskylä for Apple and Android operating systems and based on open-source technology. The application incorporates advanced AI-based methods for automatically transcribing interviews and translating the data into English when needed. This combination of front- and backend technologies expand data collection (number of interviews), reliable collection and storage, and automatic AI-based preliminary transcription, supporting the scientific quality of the research study. The mobile application's usability and integration with the university's data center backend systems ensure that data collection is easy for researchers and secure for participants.
The AI-based transcription of the collected data is performed locally in a research-dedicated server cluster (rc.jyu.fi) located at the University of Jyväskylä’s data center, which is optimized for the AI-based GPU processing and analysis of large data sets. This infrastructure ensures a high level of performance, data security, data integrity, and reliable lifecycle management, making it unique whole solution and particularly suitable for handling sensitive research data. All collected interview data, including original audio recordings, transcripts, and translations, are securely encrypted using modern encryption methods, which protect the data throughout the research process and ensure participant privacy. Authentication into the backend service (rc.jyu.fi) requires strong identity verification and two-factor authentication.
The server cluster (rc.jyu.fi) leverages modern hyperautomation, which manages the metadata and lifecycle of all collected research data, contributing to compliance with the research data management policy. The transcription process utilizes the OpenAI WhisperX Large model, based on advanced machine learning algorithms. This model can recognize and transcribe various speech styles and accents and automatically distinguish between speakers within the interview in up to 90 different languages.
The transcription results are reviewed and, if necessary, manually corrected by the research team outlined in this research plan to ensure that the data is scientifically reliable and of high quality. The server environment includes tools for reviewing and correcting the interview transcriptions. This process is essential for ensuring the quality of data analysis and conclusions. AI-based transcription accelerates the early phases of the research and frees up resources for more in-depth analysis and interpretation of results, making the research process more efficient.
The entire solution is designed specifically for the collection and handling of sensitive research data and meets strict data security and privacy requirements. The mobile application and backend service have undergone a security audit. Reliable and modern research process that produces high-quality results and enhances the impact of the research both nationally and internationally.
MyJYU AI Transcription and background service do not incur additional costs for the researcher or research project. Solution is included as part of the basic digital services provided for researchers at the University of Jyväskylä.
Description and model clause (short, suitable for funding applications)
The MyJYU AI Transcription system, developed by the University of Jyväskylä for Apple and Android, is an advanced mobile application leveraging open-source technology and AI-based methods for collecting and transcribing interview data. This comprehensive solution supports data collection, automatic transcription, and translation, ensuring ease of use, high data security, and participant privacy. The data is processed on a secure, research-dedicated server cluster optimized for GPU-based AI processing, ensuring strong data integrity and lifecycle management. The use of the OpenAI WhisperX Large model allows for accurate transcription across various accents and languages. Researchers can review and manually adjust transcriptions as needed to maintain scientific quality. Enhanced with tools for data correction and hyperautomation for metadata management, the service meets stringent security standards and complies with data policies. This efficient solution, included in the university's basic digital services at no additional cost, significantly benefits research by streamlining the transcription process and supporting high-quality, impactful outcomes.